들어가며...
Elasticsearch의 Analyzer란 Full-Text Search를 위한 방법을 정의하는 것으로 document를 저장할 때 field의 mapping type이 "text"일 경우 이에 대한 검색을 용이하게 하기 위함입니다. 입력된 text의 값을 크게 "Character Filters", "Tokenizer", "Token Filter" 3단계에 걸쳐 역색인(Inverted Index)을 함으로써 전문 검색(Full-Text Search)을 용이하게 합니다.
별다른 설정을 하지 않을 경우 standard analyzer가 설정되며 데이터의 특성에 따라 사용자가 설정할 수도 있습니다. 1차적으로 Elasticsearch에 기본적으로 built-in된 Analyzer들을 살펴보도록 하겠습니다.
- Table of Contents
- Overview
- Character Filters
- Tokenizer
- Token Filter
Overview
Elasticsearch에서는 새로운 document가 전달되었을 시 정의된 Analyzer를 이용하여 문장을 분석한 후 해당 데이터를 저장하게 됩니다. 이는 결국 전문 검색(Full-Text Search)을 용이하게 하기 위함으로 대략적인 Flow는 아래 그림과 같습니다.
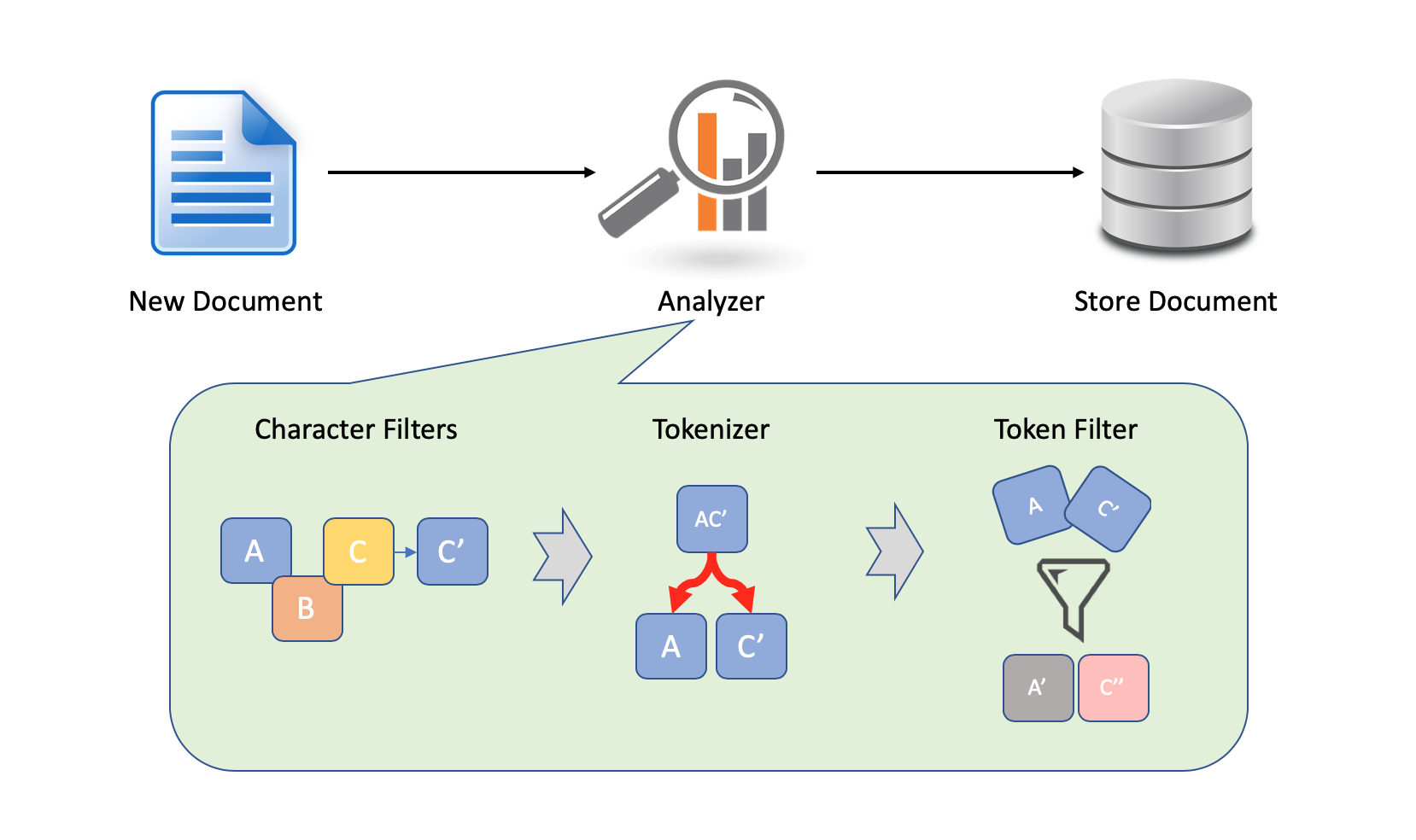
각각의 단계에서 기본적으로 제공하는 방법들이 무엇이 있는 지 살펴보기 전에 간략하게 text가 어떻게 변환되는 지 살펴보면 다음과 같습니다.

결과를 보면 알 수 있듯이 입력한 문장 'I am so Happy"가 단어 단위로 분리된 후 대문자는 소문자로 변경된 후 원래 문장에서의 시작, 끝 offset과 함께 저장되었음을 확인할 수 있습니다.
Character Filters
● HTML Strip Character Filter
HTML의 tags는 제거하고 HTML 특수문자는 decode된 문자로 변경합니다.
| Before | <p>I'm in the mood for drinking <strong>semi-dry</strong> red wine!</p> |
| After | I'm in the mood for drinking semi-dry red wine! |

● Mapping Character Filter
key, value형태로 mapping table을 정의해 놓고 key값과 일치하는 부분을 value의 값으로 치환합니다.
| Before | I'm _sad_ Are you _happy_? |
| After | I'm :- Are you :-)? |
"_sad_ ==> :-", "_happy_ ==> :-)"로 정의하였을 경우 위와 같이 변환하게 됩니다. Mapping 테이블을 정의한 후 테스트 해 봐야 하기 때문에 예제는 "링크"를 참조하시기 바랍니다.
● Pattern Replace Character Filter
정규식과 일치할 경우 정의한 값으로 치환합니다.
| Before | My credit card is 123-456-789 |
| After | My, credit, card, is, 123_456_789 |
pattern = "(\\d+)-(?=\\d)", replacement = "$1_"일 경우 위와 같이 변경됩니다.(참조링크)
Tokenizer
Tokenizer는 말 그대로 문장을 특정 규칙에 따라 분리하는 것을 의미합니다. 단순하게 공백문자로 분리할 수도 있고 아무것도 안할 수도 있으며 공백문자를 기준으로 분리하면서 소문자로 변경할 수도 있습니다. 자세한 내용은 아래의 링크를 참조하시면 되며 본 글에서는 간략하게 샘플만 짚고 넘어가도록 하겠습니다.
Tokenizer reference | Elasticsearch Reference [7.5] | Elastic
A tokenizer receives a stream of characters, breaks it up into individual tokens (usually individual words), and outputs a stream of tokens. For instance, a whitespace tokenizer breaks text into tokens whenever it sees any whitespace. It would convert the
www.elastic.co
● Word Oriented Tokenizers

● Partial Word Tokenizers

● Structured Text Tokenizers

Token Filters
Token filter는 그 수가 많은 관계로 중요한 부분에 대해서만 예시로 정리하도록 하겠습니다.

나머지 방식에 대해서는 아래의 링크를 참조하시길 바랍니다.
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenfilters.html
Token filter reference | Elasticsearch Reference [7.5] | Elastic
Token filter referenceedit Token filters accept a stream of tokens from a tokenizer and can modify tokens (eg lowercasing), delete tokens (eg remove stopwords) or add tokens (eg synonyms). Elasticsearch has a number of built-in token filters you can use to
www.elastic.co
U2ful은 ♥입니다. @U2ful Corp.
'Programming > ElasticSearch' 카테고리의 다른 글
| [Elasticsearch] 하나의 컴퓨터에 여러 개의 Node 실행시키기 (0) | 2020.01.31 |
|---|---|
| [Elasticsearch] Sample 데이터 적재/조회 하기 (0) | 2020.01.21 |
| [Elasticsearch] 맥(Mac)에 Homebrew를 사용하여 ElasticSearch 설치하기 (0) | 2020.01.10 |


